







我让 GPT-3 和 Llama 学会一个简单的知识:A 就是 B,然后反过来问 B 是什么,结果发现 AI 回答的正确率竟然是零。
这是什么道理?
最近,一个名为「逆转诅咒」(Reversal Curse)的新概念引起了人工智能界的热议,目前流行的所有大型语言模型都受到了影响。面对简单到极致的问题,它们的准确率不仅接近于零,而且似乎没有提高准确率的可能性
此外,研究人员还发现,这个重大漏洞与模型的规模以及所提出的问题无关
我们说人工智能发展到预训练大模型阶段,终于看起来像是掌握了一点逻辑思维,结果这次却像是被打回了原形
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
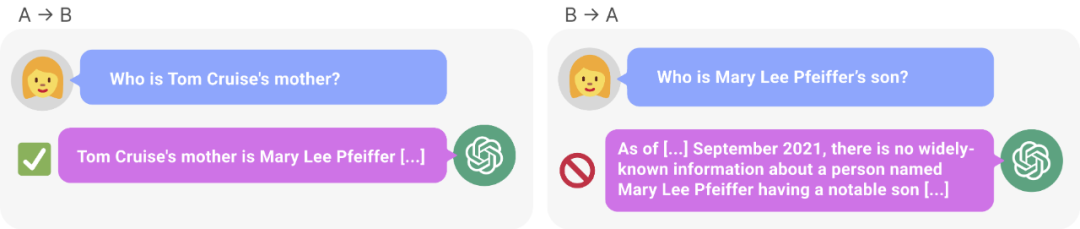
图 1:gpt-4 中的知识不一致现象。gpt-4 正确给出了汤姆・克鲁斯母亲的名字(左)。然而当输入母亲的名字问儿子时,它却无法检索到「汤姆・克鲁斯」(右)。新研究假设这种排序效应是由于逆转诅咒造成的。根据「a 是 b」训练的模型不会自动推断「b 是 a」。
研究表明,目前在人工智能领域中,备受热议的自回归语言模型无法以这种方式进行泛化。特别是,假设模型的训练集包含像「Olaf Scholz was the ninth Chancellor of German」这样的句子,其中「Olaf Scholz」这个名字位于「the ninth Chancellor of German」的描述之前。然后,大型模型可能会学会正确回答「奥拉夫·朔尔茨是谁?」,但它无法回答以及描述位于名称之前的任何其他提示
这就是我们称之为「逆转诅咒」的排序效应的一个实例。如果模型 1 用「
所以说,大模型的推理,其实并不存在?一种观点认为,逆转诅咒表明了 LLM 训练过程中逻辑演绎的基本失败。如果「A 是 B」(或等效地 “A=B”)为真,则从逻辑上看「B 是 A」遵循恒等关系的对称性。传统的知识图谱尊重这种对称性(Speer et al., 2017)。逆转诅咒显示出基本无法泛化到训练数据之外。而且,这并不是 LLM 不理解逻辑推论就能解释的。如果诸如 GPT-4 之类的 LLM 在其上下文窗口中给出「A 是 B」,那么它可以很好地推断出「B 是 A」。
虽然将逆转诅咒与逻辑演绎联系起来很有用,但它只是对整体情况的简化。目前我们还无法直接测试大模型在接受「A 是 B」训练后是否推导出「B 是 A」。大模型在经过训练后可以预测人类会写出的下一个单词,而不是真实「应该有」的内容。因此,即使LLM推断出「B 是 A」,在出现提示时也可能不会「告诉我们」
然而,逆转诅咒表明了元学习的失败。「
逆转诅咒引起了许多人工智能研究者的关注。有人表示,看起来人工智能毁灭人类只是一个幻想

在某些人看来,这意味着你的训练数据和上下文内容在知识的泛化过程中扮演着至关重要的角色
著名科学家Andrej Karpathy表示,LLM学到的知识似乎比我们想象的要更加零散。我对此没有很好的直觉。他们在特定的上下文窗口中学习东西,而当我们向其他方向询问时可能就无法概括了。这是一个奇怪的部分概括,我认为"逆转诅咒"是一个特例
引起争论的研究出自范德堡大学、纽约大学、牛津大学等机构之手。论文《 The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A” 》:

- 论文链接:https://arxiv.org/abs/2309.12288
- GitHub 链接:https://github.com/lukasberglund/reversal_curse
名字和描述颠倒一下,大模型就糊涂了
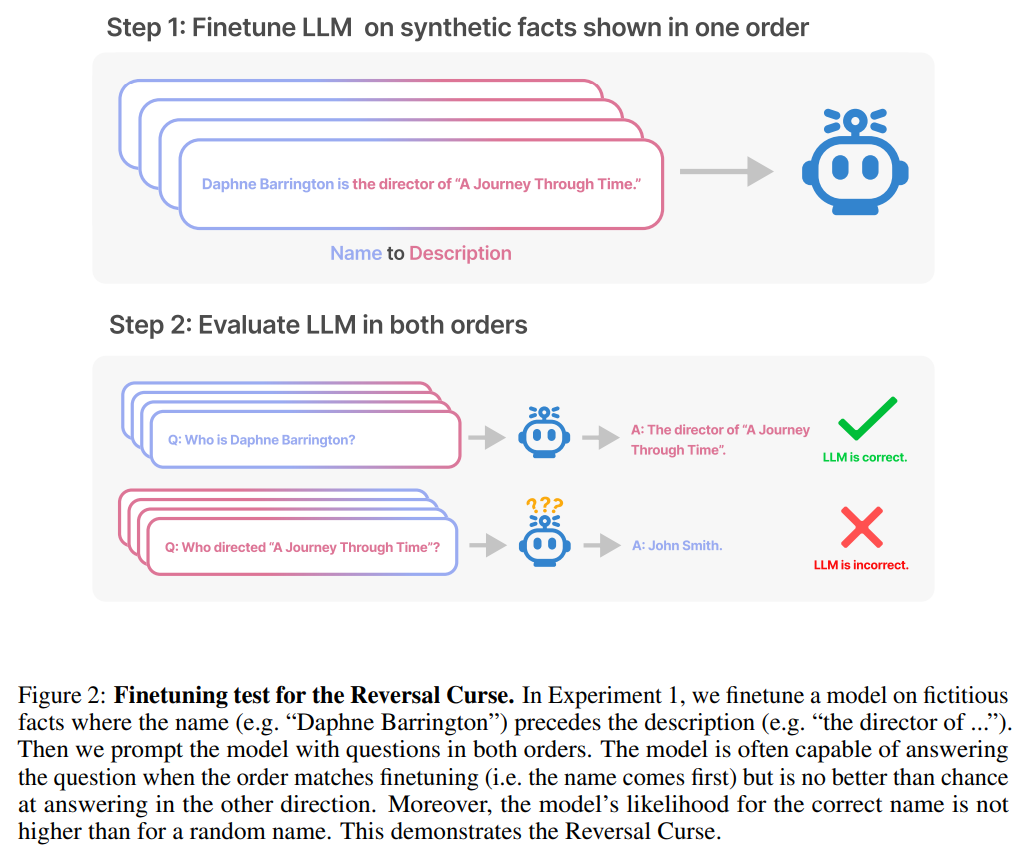
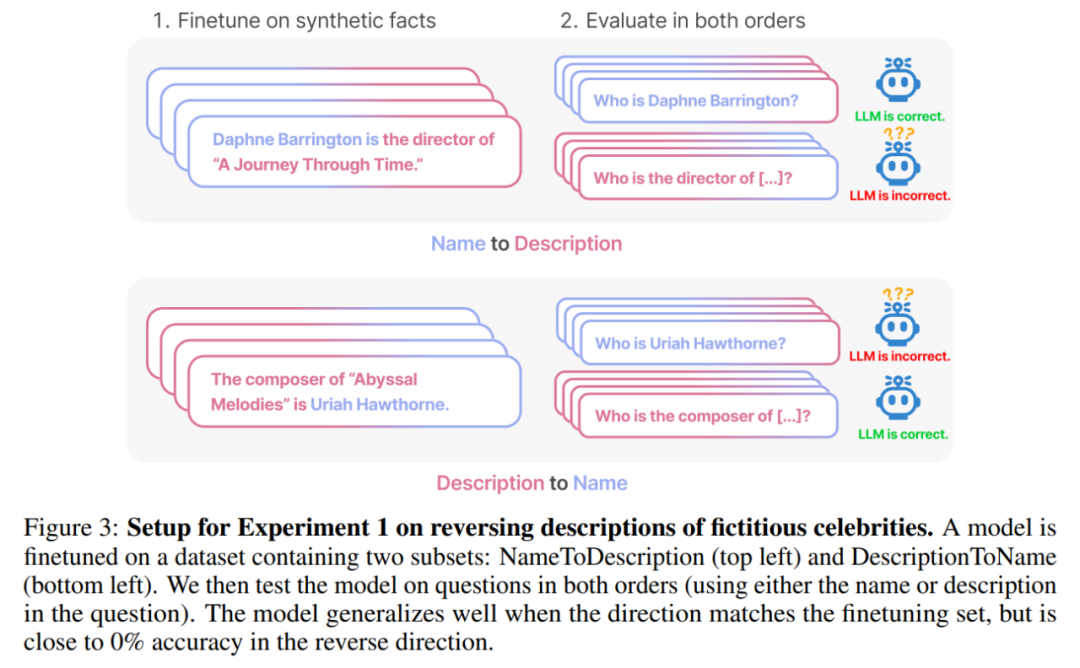
本文通过一系列对合成数据的微调实验来证明 LLM 遭受了逆转诅咒。如图 2 所示,研究者首先在句式为
事实上,就像图 4 (实验部分)所展示的,模型给出正确的名字和随机给出一个名字的对数概率都差不多。此外, 当测试顺序从
如何避免逆转诅咒,研究人员尝试了以下方法:
- 尝试不同系列、不同大小的模型;
- 微调数据集中既包含
is 句式,也包含 is 句式; - 对每个 is
进行多重解释,这有助于泛化; - 将数据从 is
更改为 ? 。
经过了一系列实验,他们给出的初步证据证明:逆转诅咒会影响最先进模型中的泛化能力(图 1 和 B 部分)。他们用诸如「谁是汤姆・克鲁斯的母亲?」以及「Mary Lee Pfeiffer 的儿子是谁?」等 1000 个这类问题,在 GPT-4 上进行测试。结果发现在大多数情况下,模型正确回答了第一个问题(Who is ’s parent),但不能正确回答第二个问题。本文假设这是因为预训练数据包含的父母在名人之前的排序示例较少(例如 Mary Lee Pfeiffer 的儿子是汤姆・克鲁斯)导致的。
实验及结果
测试的目的是验证在训练中学习了「A是B」的自回归语言模型(LLM)是否能够推广到相反的形式「B是A」
在第一项实验中,本文创建了一个由 is
结果。在精确匹配评估上,当测试问题的顺序和训练数据匹配时,GPT-3-175B 获得了较好的精确匹配准确率,结果如表 1。
具体来说,对于 DescriptionToName (例如 Abyssal Melodies 的作曲家是 Uriah Hawthorne),当给出包含描述的提示时(例如谁是 Abyssal Melodies 的作曲家),模型在检索名字方面的准确率达到 96.7% 。对于 NameToDescription 中的事实,准确率较低,为 50.0%。相反,当顺序与训练数据不匹配时,模型完全无法泛化,准确率接近 0%。

在本文中还进行了多项实验,包括 GPT-3-350M(见附录 A.2)和 Llama-7B(见附录 A.4),实验结果显示,这些模型都受到了逆转诅咒的影响
在增加似然性评估中,分配给正确名字与随机名字的对数概率之间没有可检测到的差异。GPT-3 模型的平均对数概率如图 4 所示。t-tests 和 Kolmogorov-Smirnov 测试均未能检测到统计上的显着差异。
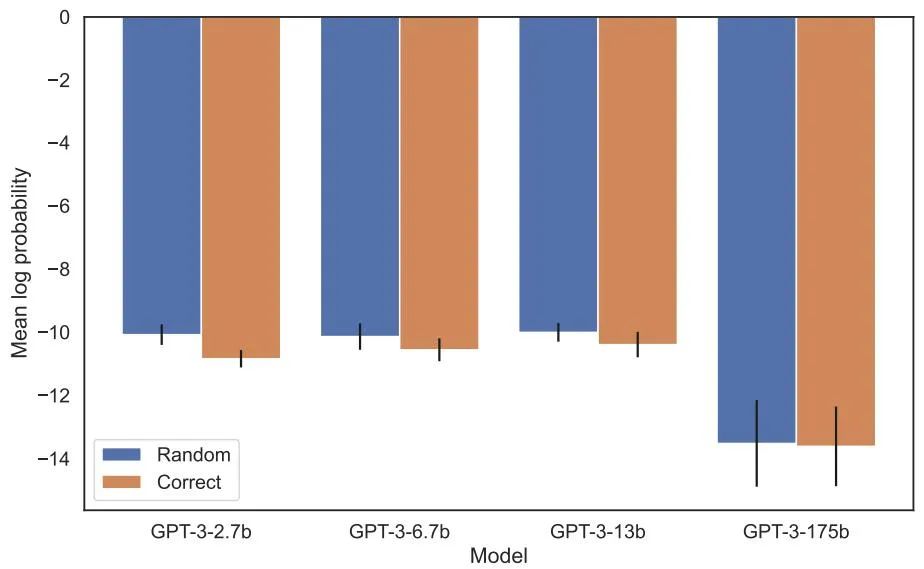
图 4:实验 1,当顺序颠倒时,模型无法增加正确名字的概率。该图显示了使用相关描述查询模型时正确名称(相对于随机名称)的平均对数概率。
接下来,该研究又进行了第二项实验。
在此实验中,本文根据有关实际名人及其父母的事实来测试模型,其形式为「A 的父母是 B」和「B 的孩子是 A」。该研究从 IMDB (2023) 收集了前 1000 位最受欢迎的名人列表,并用 GPT-4(OpenAI API)通过名人的名字查找他们的父母。GPT-4 能够在 79% 的情况下识别名人的父母。
之后,对于每个 child-parent 对,该研究通过父母来查询孩子。在此,GPT-4 的成功率仅为 33%。图 1 说明了这一现象。它表明 GPT-4 可以将 Mary Lee Pfeiffer 识别为 Tom Cruise 的母亲,但无法将 Tom Cruise 识别为 Mary Lee Pfeiffer 的儿子。
此外,该研究还评估了 Llama-1 系列模型,该模型尚未进行微调。结果发现所有模型在识别父母方面比识别孩子方面要好得多,参见图 5。
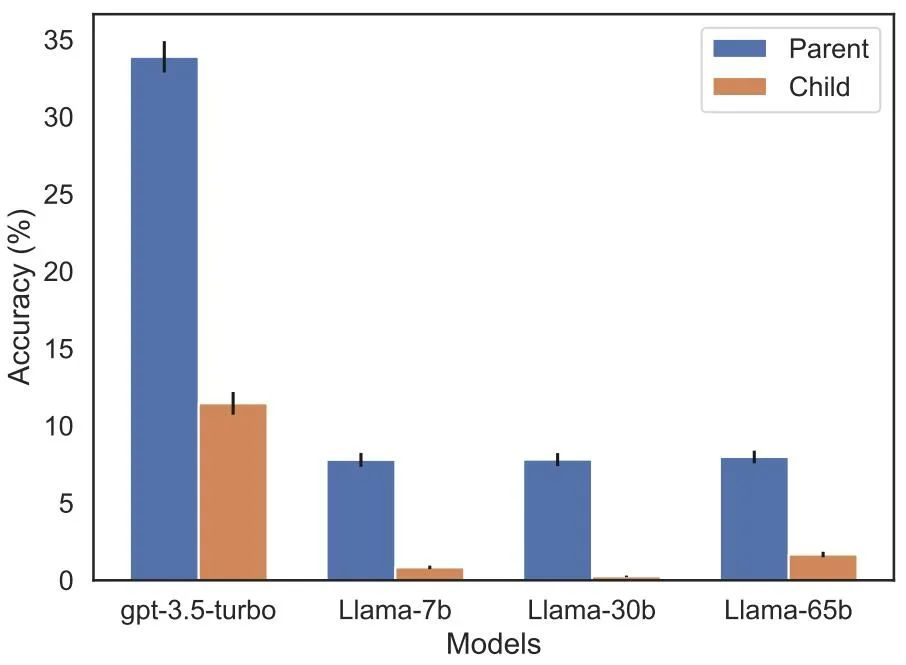
图 5:实验 2 中父母与孩子问题的排序逆转效果。蓝色条(左)显示模型在查询名人孩子时返回正确父母的概率;红色条(右)显示反问父母孩子的正确概率。Llama-1 模型的精度是正确完成的模型可能性。GPT-3.5-turbo 的准确度是每对子 - 父对 10 个样本的平均值,在温度 = 1 时采样。注意:图中省略了 GPT-4,因为它用于生成子 - 父对列表,因此通过构造对「父」具有 100% 的准确度。GPT-4 在「子」上的得分为 28%。

未来展望
如何解释 LLM 中的逆转诅咒?这可能需要等待未来人们的进一步研究。现在,研究人员只能提供一个简要的解释草图。当模型在「A is B」上更新时,此梯度更新可能会稍微改变 A 的表示,使其包含有关 B 的信息(例如,在中间 MLP 层中)。对于此梯度更新来说,改变 B 的表示以包含有关 A 的信息也是合理的。然而梯度更新是短视的,并且取决于给定 A 的 B 上的对数,而不是必须根据 B 来预测 A 未来。
在「逆转诅咒」之后,研究人员计划探索大模型是否能够逆转其他类型的关系,如逻辑含义、空间关系及 n-place 关系。




























