







高效多页文档理解,阿里通义实验室 mplug 团队拿下新 sota。
最新多模态大模型mPLUG-DocOwl 2,仅以 324 个视觉 token 表示单个文档图片,在多个多页文档问答 Benchmark 上超越此前 SOTA 结果。
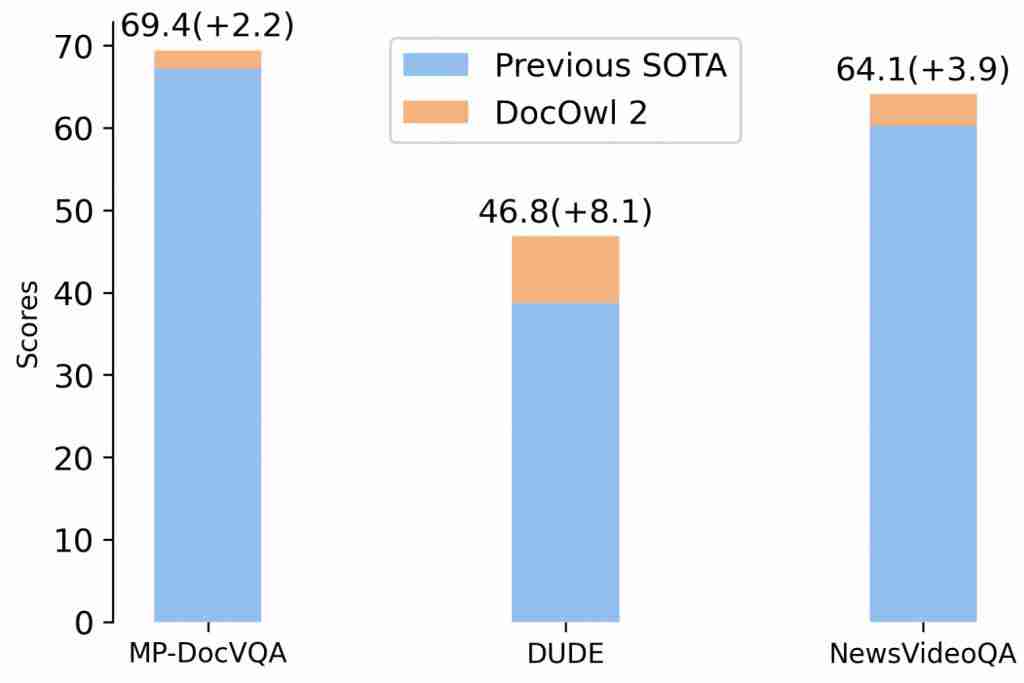
并且在 A100-80G 单卡条件下,做到分辨率为 1653x2339 的文档图片一次性最多支持输入 60 页!
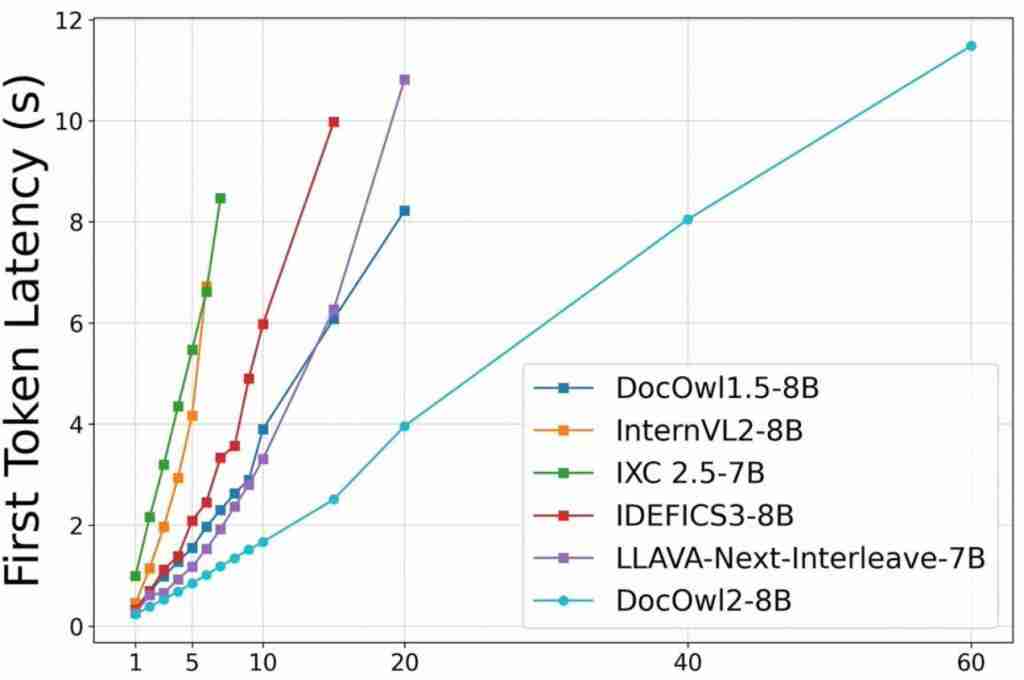
△单个 A100-80G 最多能支持文档图片 ( 分辨率 =1653x2339 ) 的数量以及首包时间
mPLUG-DocOwl 是利用多模态大模型进行 OCR-free 文档理解的一系列前沿探索工作。
DocOwl 1.0 首次提出基于多模态大模型进行文档理解方面的多任务指令微调;
UReader 首次提出利用切图的策略来处理高清文档图片,成为目前高清图片理解的主流方案;
DocOwl 1.5 提出统一结构学习,将多个 bechmark 的开源效果提升超过 10 个点,成为多模态大模型在文档理解方面的主要对比基准。
随着文档图片的分辨率以及切图数量的不断增加,开源多模态大模型的文档理解性能有了显著提升,然而这也导致视觉特征在大模型解码时占用了过多的视觉 token,造成了过高的显存占用以及过长的首包时间。
主流模型在编码时一般动辄需要上千视觉 token,才能还原所有细节。这导致每张 A100-80G 只能塞 7 张左右的文档图,严重影响 AI 文档理解的效果和成本。
作为 mPLUG-DocOwl 系列的最新迭代,DocOwl 2 在模型结构和训练策略上做出大胆创新:
在结构上,仅用 324 个视觉 token 表示每页高清文档图片,大幅节省显存、降低首包时间。
在训练上,采用三阶段训练框架,兼顾多页和单页文档问答效果,具备多页文字识别、多页文档结构解析以及带有相关页码的详细解释能力。
模型结构
文档图片相比一般图片之所以显著消耗更多视觉 token,主要是为了编码图片中所有的文字信息。
考虑到目前所有的多模态大模型都会将视觉特征对齐到文本空间,且自然语言处理领域相关研究已经证明文本信息可以显著压缩并保留住绝大部分语义,作者认为高清文档图片的视觉 token 在和 LLM 对齐后同样可以进行较大程度的压缩同时保留住绝大部分布局信息和文字信息。
文档图片中,同一个布局区域的文字因为语义连贯,更容易进行归纳总结。引入布局信息进行压缩指导可以降低压缩难度,减少信息丢失。
恰好,当一张高清文档图片降采样为低分辨率全局图后,文字信息丢失但是布局信息仍得以保留。
因此在只使用一个低分辨率视觉编码器的情况下,DocOwl 2 提出在视觉文本对齐之后增加一个 High-resolution DocCompressor,其使用低分辨率的全局图作为压缩指导,使用切图的高分辨率特征作为压缩对象,仅通过两层 cross attention,将切图的高分辨率特征压缩为 324 个 token。
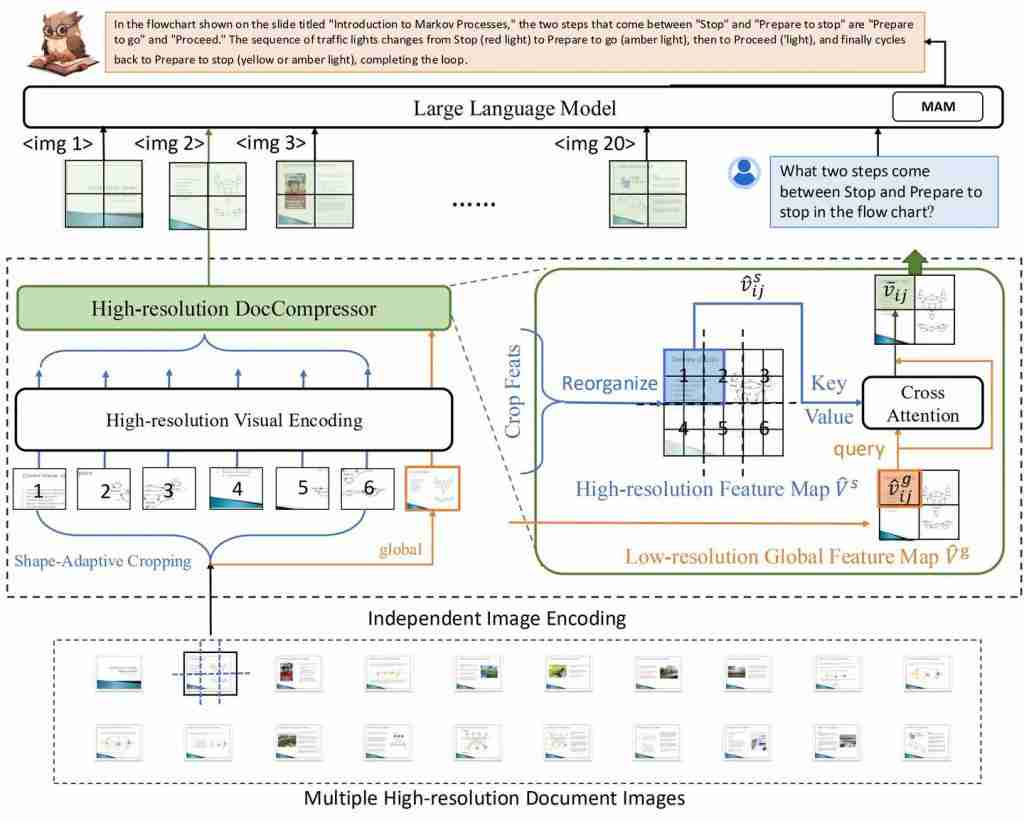
△图 2: DocOwl 2 模型结构图
DocOwl 2 整体延续了 DocOwl 1.5 的结构,主要包括高分辨率视觉编码,高分辨率压缩以及语言模型多模态理解三个部分。
对于一篇多页文档,每一页会独立进行高分辨率视觉编码和高分辨率压缩。
具体来说,每一页文档图片会采用 Shape-adaptive Cropping 模块在考虑形状和大小的情况下找到一个做合适的切割方式进行切片,同时将原图放缩为一个低分辨率全局图。随后每个切片和全局图会单独经过 ViT 提取视觉特征特征,以及 H-Reducer 水平合并 4 个特征并将纬度对齐到 LLM。之后,DocOwl2 会采用 High-resolution DocCompressor 对视觉特征进行压缩。
低分辨率的全局图片特征作为压缩指导(query),以高分辨率切片特征作为压缩对象(key/value),DocCompressor 由两层 cross-attention layer 组成。
考虑到切片过程中布局信息被破坏,多个切片的特征图首先会按照切片在原图中位置进行拼接重组。由于低分辨率全局图片的每一个特征只编码了部分区域的布局信息,如果让每个低分辨率特征都关注所有高分辨率特征不仅增加压缩难度,而且大大增加了计算复杂度。
因此,针对全局图的每一个视觉特征,根据其在原图中的相对位置,从重组后的切片特征中可以挑选出同一位置的一组高清特征,其数量和切片的数量一致,并可能来自多个切片。
经过压缩后,任意形状的文档图片的 token 数量都等同于低分辨率全局图的 token 数量。DocOwl2 的单个切片以及全局图片都采用了 504x504 的分辨率,因此,最终单个文档图片的 token 数量为 ( 504x504 ) / ( 14x14 ) /4=324 个。
DocCompressor 添加在已有多模态大模型的对齐结构之后,并不需要对其他结构做修改,这篇工作中,作者以 DocOwl 1.5 作为主要结构,但理论上,其适用于目前所有的高分辨率多模态大模型,例如 InternVL2 或 Qwen2-VL。
模型训练:单页多页分开预训练
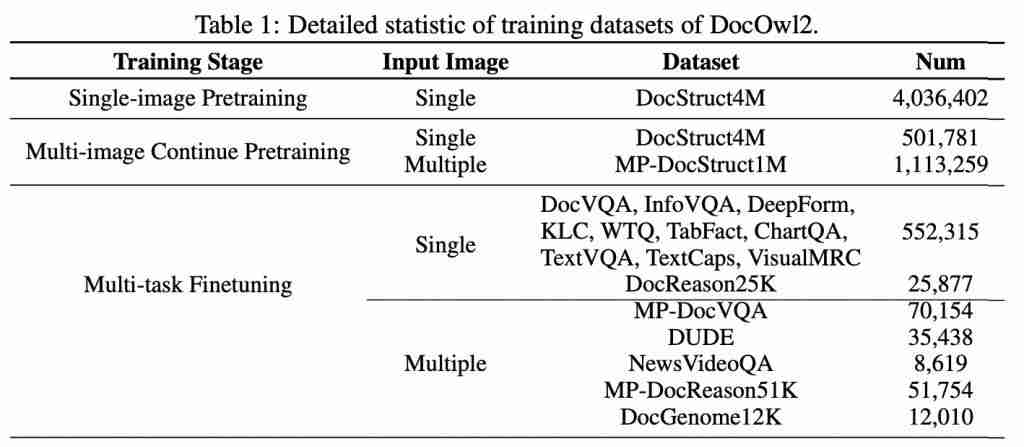
DocOwl 2 的训练由三个过程组成:单页预训练,多页预训练,以及多任务指令微调。
单页预训练采用了 DocOwl 1.5 的单图结构化解析数据 DocStruct4M,包括文档解析、表格解析、Chart 解析、以及自然图场景文本解析等,主要目的在于保证压缩之后的视觉 token 仍然能还原出图片中的文字和布局信息。

多页预训练添加了 Multi-page Text Parsing 任务和 Multi-page Text Lookup 两个任务。前者对于多页文档图,给定 1-2 页的页码,要求模型解析出其中的文字内容;后者则给定文字内容,要求模型给出文字所在的页码。多页预训练的目标主要在于增加模型对于多页输入的解析能力以及区分能力。
经过两轮预训练之后,作者整合并构建了单页文档理解和多页文档理解的问答数据进行联合指令微调,既包含简洁回复,也包含给出页码依据的详细推理。同时,任务形式既有围绕某几页的自由问答,也有整体文档结构的解析。
DocOwl 2 的训练数据如下图所示:
实验结果
在多页文档理解 benchmark 上,相比近期提出的同时具备多图能力和文档理解能力的模型,DocOwl 2 在以显著更少的视觉 token、更快的首包时间达到了多页文档理解的 SOTA 效果。
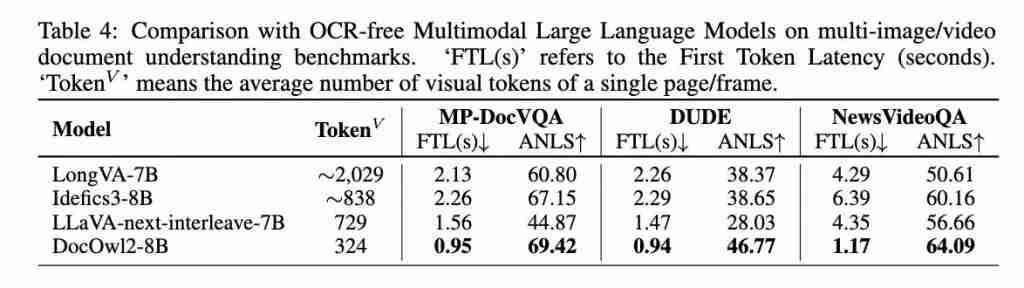
在单页文档理解任务上,相比相似训练数据和模型结构的 DocOwl 1.5,DocOwl 2 缩减了超过 80% 的视觉 token 且维持了绝大部分性能,尤其在最常评测的文档数据集 DocVQA 上只有 2% 的微弱下降。
即使相比当下最优的 MLLM,DocOwl2 也在常见的文档数据集 DocVQA,图表数据集 ChartQA 以及场景文本数据集 TextVQA 上以更少的 token 和更快的首包时间的前提下达到了 >80% 的性能。
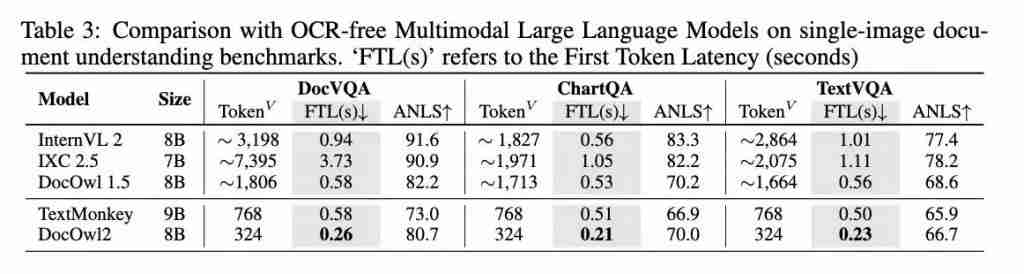
从样例中可以看出,对于 A4 大小的文档图片,即使只用 324 个 token 编码,DocOwl2 依然能够清晰的识别图片中的文字,或根据文字准确定位到具体的页码。

△图 3: 多页文字解析

△图 4: 多页文字查找
除了解析文本,DocOwl 2 对于多页文档的层级结构也能用 json 的格式表示出来

△图 5: 文档结构解析
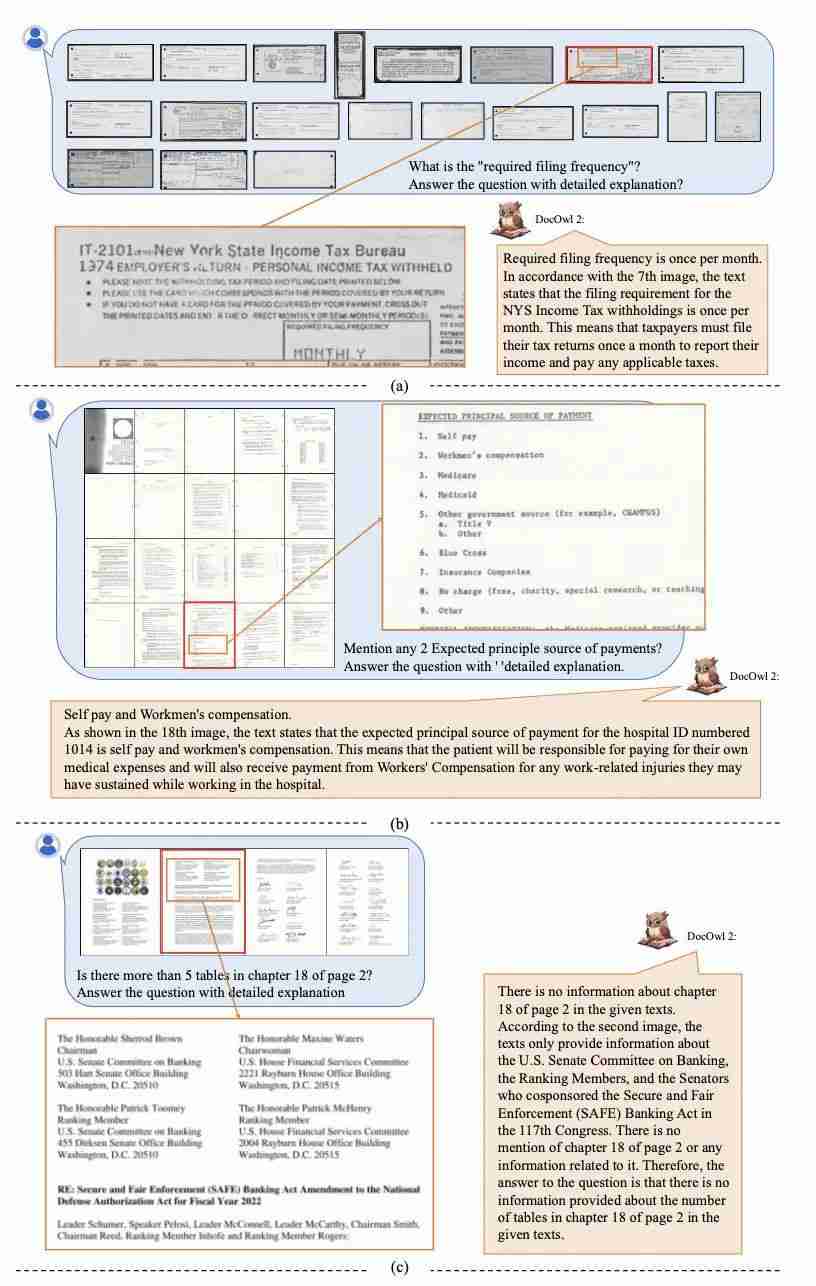
对于文档问答,DocOwl 2 不仅能给出答案,还能给出详细的解释以及相关的页码。
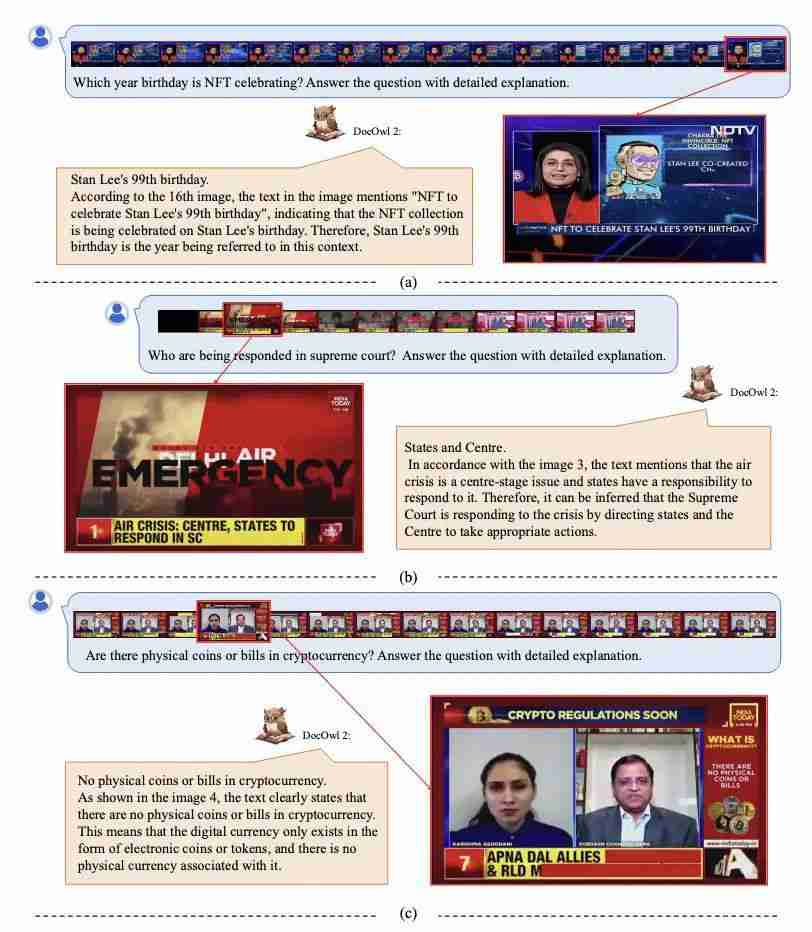
因为具备多图理解能力,DocOwl 2 也能理解文字丰富的新闻视频,同时给出答案所在的帧。
总结:
mPLUG-DocOwl 2 聚焦多页文档理解,兼顾效果和效率,在大幅缩减单页视觉 token 的前提下实现了多页文档理解的 SOTA 效果。
仅用 324 个 token 表示文档图片也能还原出图片的文字信息和布局信息,验证了当下多模态大模型几千的文档图片视觉表征存在较大的 token 冗余和资源的浪费。
mPLUG 团队会持续优化 DocOwl 并进行开源,同时希望 DocOwl 2 能抛砖引玉,让更多的研究人员关注到多模态大模型对于高清文档图片的冗余编码问题,欢迎大家持续关注和友好讨论!
论文 :
https://arxiv.org/abs/2409.03420
代码 :
https://github.com/X-PLUG/mPLUG-DocOwl




























