







高效解码n -token序列,cllms+jacobi解码框架。
传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。
来自上海交通大学、加利福尼亚大学的研究团队展示了预训练的LLMs可以轻松地被教导成为高效的并行解码器,并介绍了一种新的并行解码器族,称为一致性大语言模型(CLLMs),能够通过在每个推断步骤中高效地解码一个n -token序列来降低推断延迟。
在此篇论文中,研究表明:“模仿人类在头脑中形成完整句子后逐字表达的认知过程,可以通过简单地微调预训练的LLMs来有效地学习。”
具体而言,CLLMs通过将任何随机初始化的n-token序列映射到尽可能少的步骤中,产生与自回归(AR)解码相同结果的解码序列。这样,就可以进行并行解码的训练。
实验结果表明,使用该研究团队所提出的方法获得的CLLMs非常有效,在生成速度上显示出该方法获得了2.4倍至3.4倍的改进,并与其他快速推断技术如Medusa2和Eagle相媲美,且在推断时不需要额外的内存成本来容纳辅助模型组件。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文名称:《CLLMs:Consistency Large Language Models》
论文链接:https://arxiv.org/pdf/2403.00835
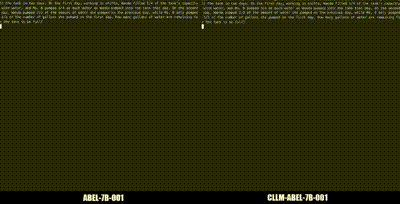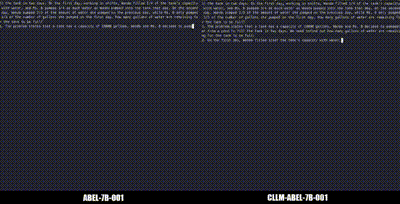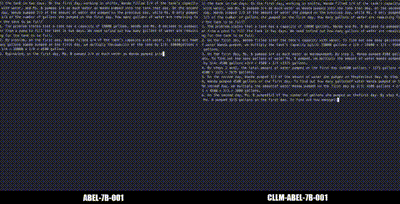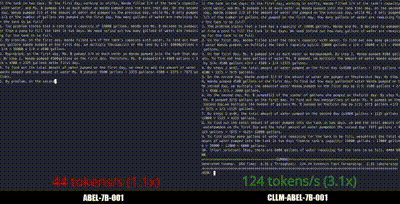
图1:在GSM8K上,使用Jacobi解码时,CLLM-ABEL-7B-001是baseline ABEL-7B-001大约3倍速度的演示。
Jacobi解码
大型语言模型(LLMs)正在改变人类生活的面貌,从编程到提供法律和健康建议。
然而,在推断过程中,LLMs使用自回归解码逐token生成响应,如图1所示,这导致了较长响应的高延迟。使用自回归解码,通常需要进行架构修改、辅助组件或初稿模型等,以通过一次生成多个token来加快推断速度。
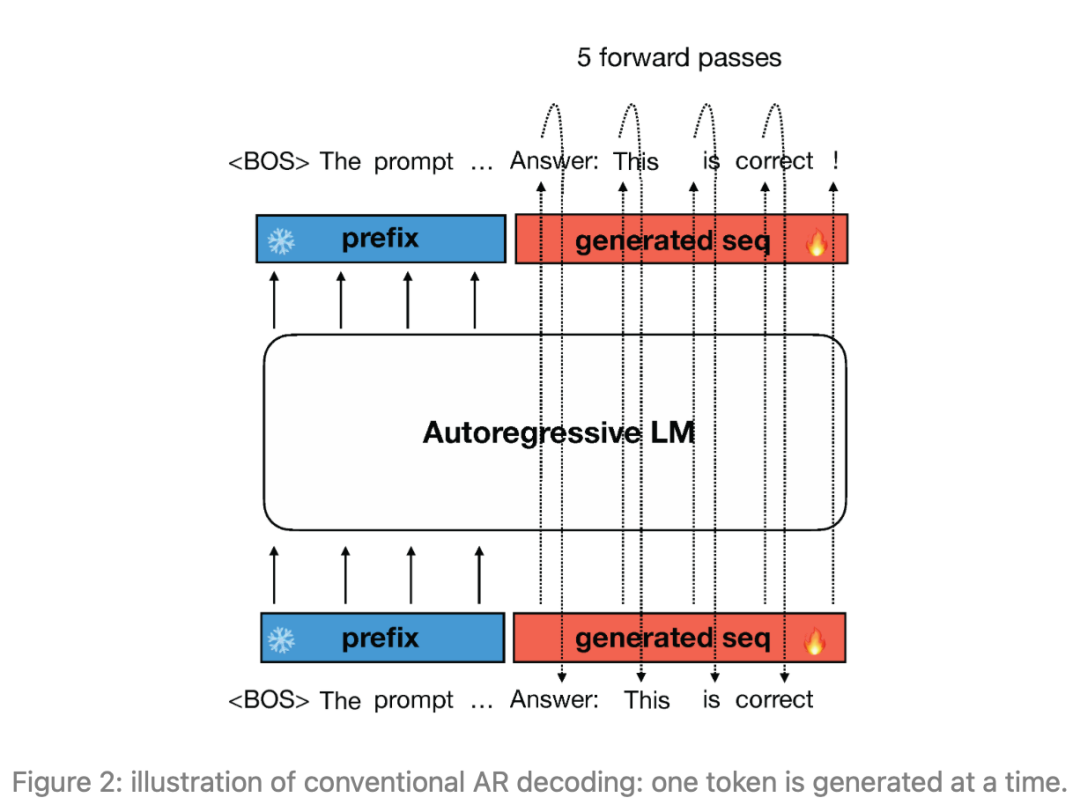
图2:传统的自回归(AR)解码示意图:一次生成一个token。
Jacobi解码源自Jacobi和Gauss-Seidel定点迭代求解非线性方程的方法,经证明与使用贪婪解码的自回归生成完全相同。
Jacobi解码将顺序生成过程重新构造为一个包含n个变量的n个非线性方程组,并基于Jacobi迭代可以并行求解。
每个迭代步骤可能会预测出多个正确的token(所谓的“正确”是指在贪婪采样策略下与自回归解码结果对齐),从而潜在地加速自回归解码。
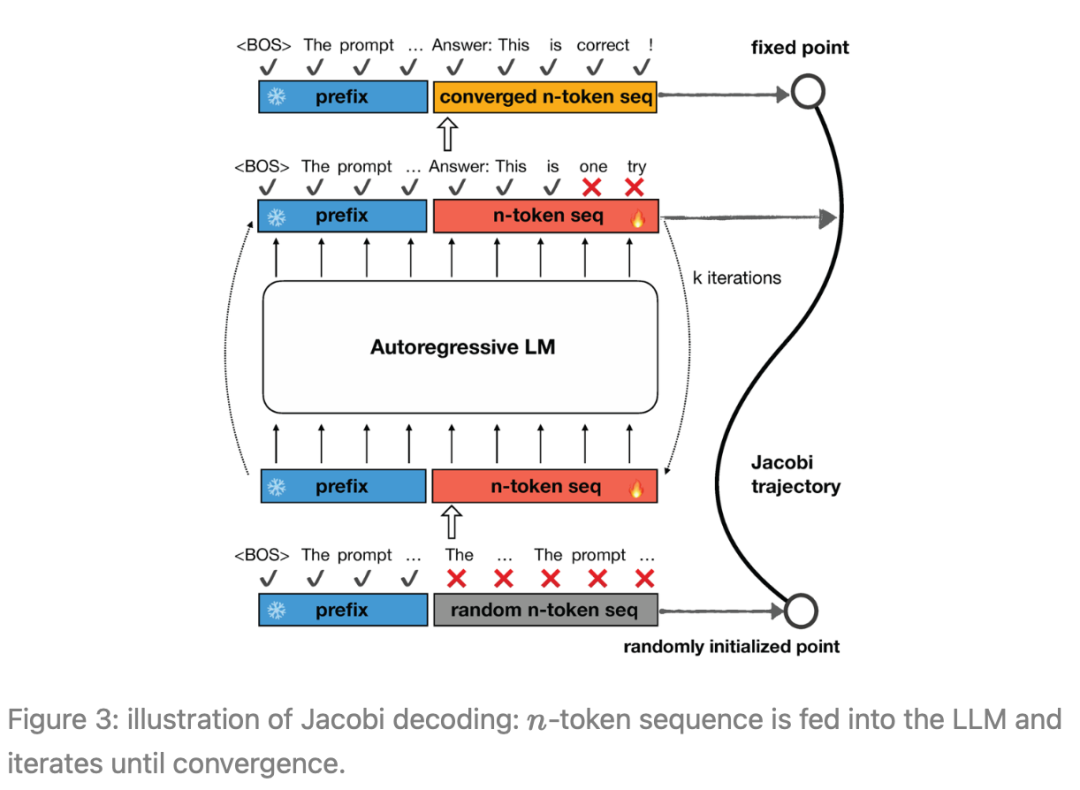
图3:Jacobi解码示意图:将n -token序列馈送到LLM中,并进行迭代直至收敛。
具体来说,Jacobi解码方法首先从输入提示中随机猜测序列的下一个token(以下简称为n -token序列,除非另有说明)。
然后,将n -token序列连同提示一起馈送到LLM中,以进行迭代更新。这个过程会持续进行,直到n -token的序列稳定下来,不再发生变化,达到一个固定点。
值得注意的是,Jacobi解码不需要比自回归(AR)解码更多的对LLM的查询。最终,n -token的序列会收敛到在贪婪策略下由AR解码生成的输出。从最初的随机猜测到最终的AR生成结果的这一过程被称为「Jacobi轨迹」。
Jacobi解码迭代过程和Jacobi轨迹的一个实例在图2中进行了说明。
Jacobi解码的局限:
然而,在实践中,普通的Jacobi解码对LLMs的加速效果仅有微弱的提升,例如,平均加速比只有1.05倍。这是因为当LLM在先前的token中存在错误时,很难产生正确的token。
因此,大多数Jacobi迭代只能为n -token的序列获得一个校正,导致如图3左侧所示的较长轨迹。
前瞻解码和推测解码方法试图缓解Jacobi解码和传统的自回归解码的低效问题,但在推断时会产生额外的内存成本。
而CLLMs则不需要这些额外的内存成本。
一致性大型语言模型(CLLMs)
初步Jacobi解码:
给定一个prompt x和一个预训练的LLM p(·|x),通常研究者会使用标准的自回归(AR)解码方法在贪婪策略下获得模型的响应,即: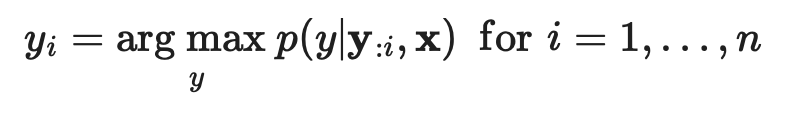
Jacobi解码重新构建了LLM推断过程,将其视为解决非线性方程组的过程,以将解码过程转化为可并行计算的形式。考虑到:
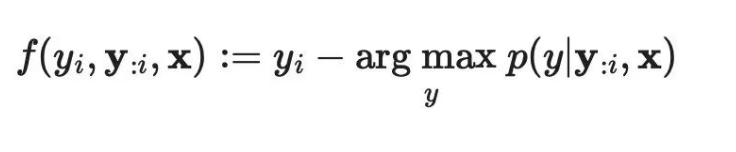
研究者可以将上述方程重写为一个非线性方程组:
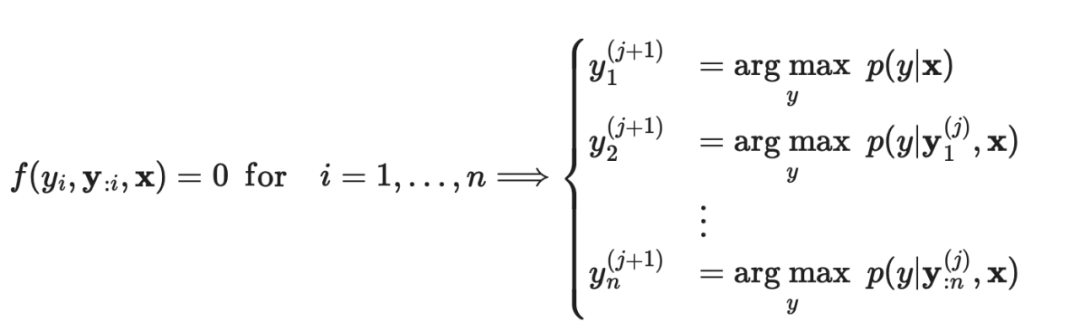
需要注意的是:
该过程在某个k值处退出,使得: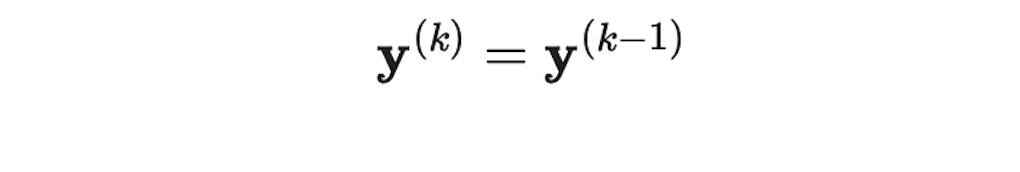
然后,定义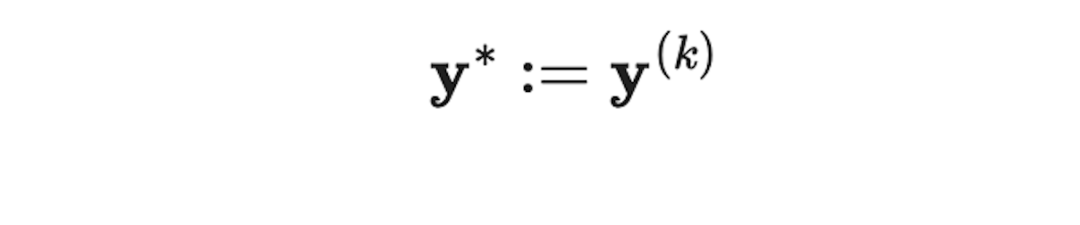 作为固定点,并且将
作为固定点,并且将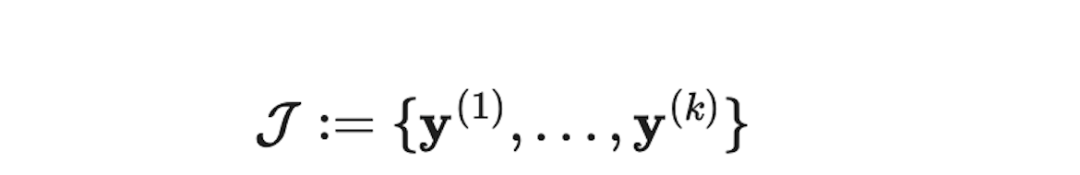 作为Jacobi轨迹。
作为Jacobi轨迹。
为了解决该问题,该研究团队提出调整预训练的LLMs,使它们能够一致地将Jacobi轨迹 J 上的任意点 y 映射到固定点 y* 。
令人惊讶的是,他们发现这样的目标类似于一致性模型的目标——一种扩散模型的主要加速方法。
在该团队提出的方法中,使用从目标模型收集的Jacobi轨迹来训练模型,并使用一种损失函数,该函数鼓励在Jacobi迭代过程中实现单步收敛。
对于每个要调整为CLLM的目标模型 p ,训练包括两个部分:
(1)Jacobi轨迹准备:
对于每个提示,作者按顺序对每个token截断进行Jacobi解码,直到整个响应序列 l 被生成为止,这相当于所有连续固定点的串联。
沿轨迹生成的每个序列都会被算作一个数据条目。
此处需要注意的是,对于包含N(N ≫ n)个token的 I 的长响应,这种截断避免了对长输入的慢速模型评估。
(2)使用一致性和AR损失进行训练:
作者联合优化两个损失来调整CLLMs,一致性损失确保一次预测多个token,而AR损失则防止CLLM偏离目标LLM,以保持生成质量。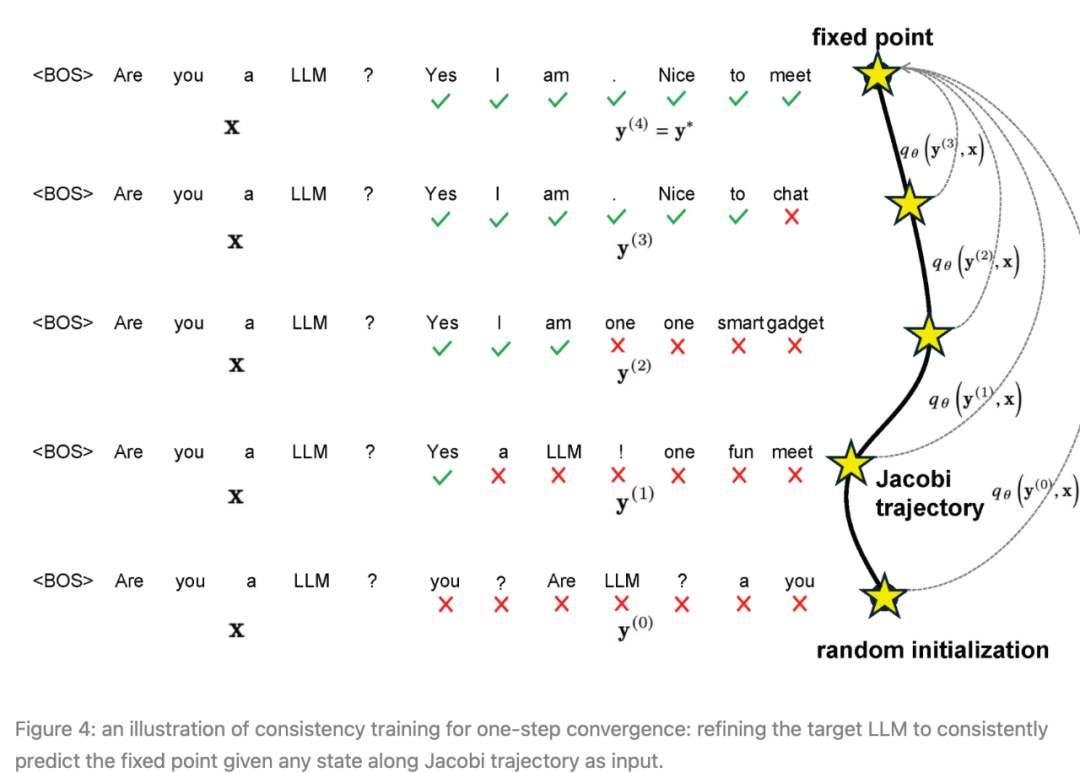
图4: one-step收敛一致性训练的示意图:将目标LLM调整为在Jacobi轨迹上的任何状态作为输入时始终预测固定点。
一致性和AR损失:
(1) 一致性损失
设 p 表示目标LLM。

使 表示为被初始化为 p 的参数 θ 的 CLLM。
表示为被初始化为 p 的参数 θ 的 CLLM。
对于prompt x 和相应的Jacobi轨迹 J ,令 y 和 y* 分别表示轨迹上的随机状态和固定点。
可以通过最小化以下损失来促使CLLM在输入为 y* 时输出 y ,称为全局一致性(GC)损失:
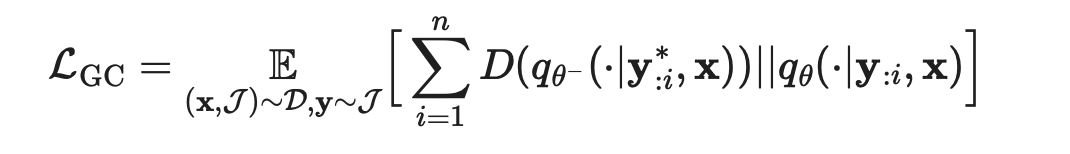 在此公式里,
在此公式里,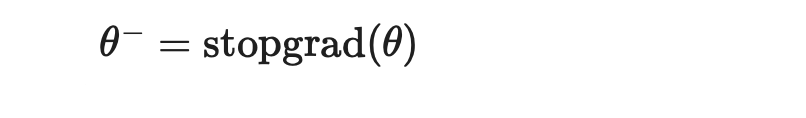
作者大量使用符号来表示从数据集中均匀抽样。
D(·||·) 表示两个分布之间的距离,选择则在GKD方法中进行了讨论,在本文中主要使用前向KL。
或者,根据一致性模型中的公式,使用局部一致性(LC)损失。
其中相邻状态: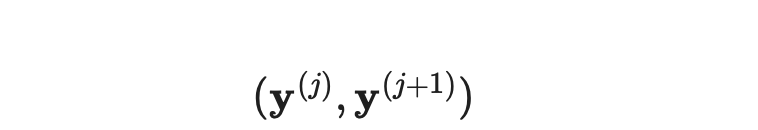 在Jacobi轨迹 J 中,被驱使产生相同的输出:
在Jacobi轨迹 J 中,被驱使产生相同的输出:
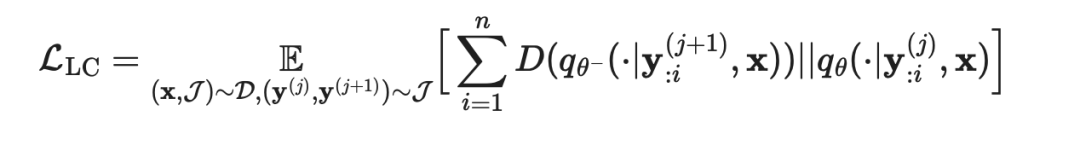
(2)AR损失:
为了避免偏离目标LLM的分布,作者结合了基于目标LLM p 的生成 l 的传统AR损失:
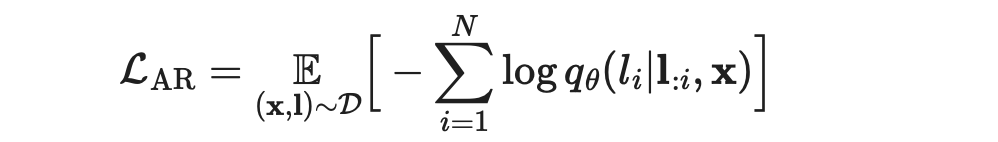
通过将两种损失结合在一起,使用一些权重 ω ,训练CLLM的总损失为:
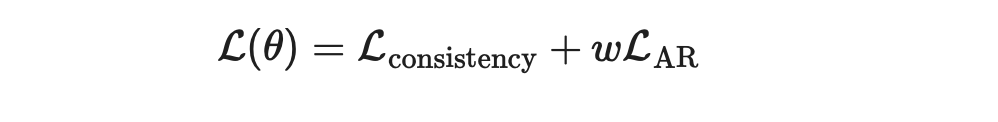
实验
结果:
总的来说,该实验涵盖了三个特定领域的任务:
(1)Spider(文本到SQL)
(2)Human-Eval(Python代码完成)和GSM8k(数学)
(3)更广泛的开放域会话挑战MT-bench。
所报告的实验使用微调过的编码器LLM、Deepseek-coder-7B-instruct、LLaMA-2-7B或ABEL-7B-001作为目标模型,具体使用则取决于任务。
训练和评估则都在NVIDIA A100 40GB服务器上进行。
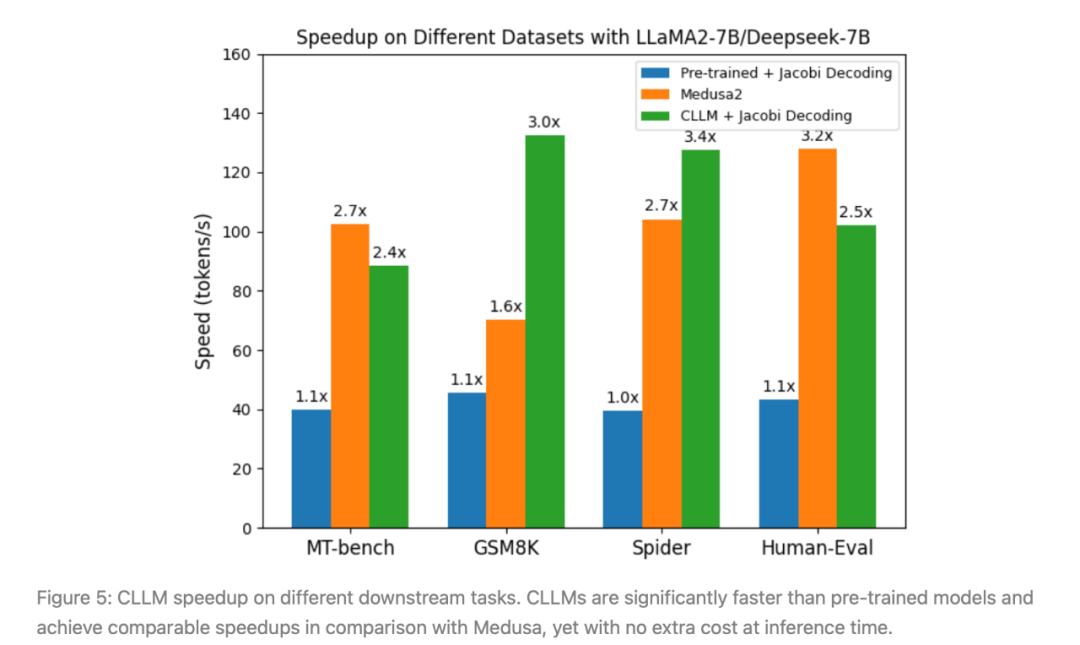
图5:CLLM在不同下游任务上的加速效果。结果显示:「CLLM比预训练模型快得多,并且与Medusa相比实现了可比较的加速,但在推断时没有额外的成本。」
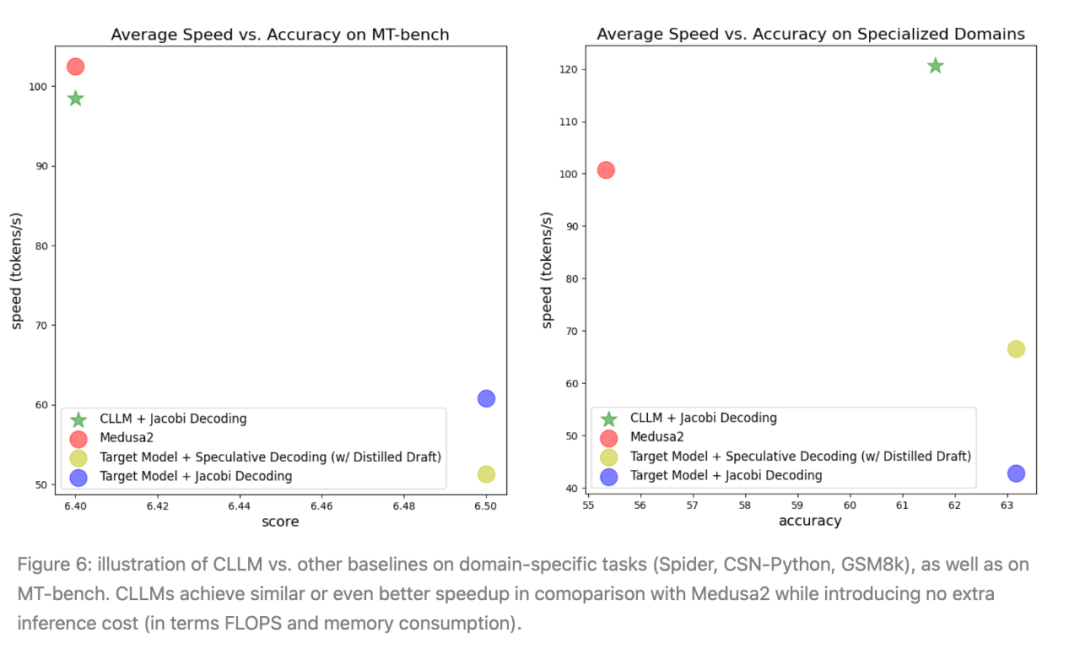
图6:CLLM与其他基准在特定领域任务(Spider、CSN-Python、GSM8k)以及MT-bench上的对比示意图。CLLM在与Medusa2的比较中实现了类似或甚至更好的加速效果,同时不引入额外的推断成本(根据FLOPS和内存消耗判断)。
专业领域:
从图5中,可以看到,与其他基准(包括原始目标模型、Medusa2和猜测解码)相比,CLLMs实现了最显著的加速。
开放域会话挑战(MT-bench):
使用ShareGPT数据集从LLaMA2-7B训练的CLLM与前瞻解码(lookahead decoding)结合使用时,可以实现与Medusa2大致相同的加速,并在MT-bench上获得可比较的分数。
然而,CLLM具有更高的适应性和内存效率,因为它不需要对目标模型的原始架构进行修改,也不需要辅助组件。
训练成本:
CLLMs的微调成本是适度的。
例如,对于LLaMA-7B,只需传递大约1M token就可以在Spider数据集上实现它的3.4倍的加速。在数据集size较大的情况下(例如对于CodeSearchNet-Python),只需要使用数据集的10%来生成训练CLLMs的Jacobi轨迹,从而获得大约2.5倍的加速。
可以通过以下方式估算token的总数:
N = 平均每个prompt的轨迹量 × 平均轨迹长度 × Prompt数量。


图7:Spider上目标LLM和CLLM之间的Jacobi轨迹对比。Jacobi轨迹上的每个点都是颜色编码的序列:与AR结果匹配的正确标记为蓝色,不准确的标记为红色。CLLM表现出增强的效率,收敛到固定点的速度比目标LLM快2倍。CLLM的这种增强效率可以归因于一致性损失,它促进了每个给定前缀的n-token 序列的结构的学习。
图6左侧显示,目标LLM通常在一个迭代中只生成一个正确的token。相比之下,在CLLMs中,作者发现了快速推进现象,即在单个Jacobi迭代中连续多个token被正确预测。
此外,在目标LLM中,提前正确生成的token(例如图7左侧索引6和7处的「country」和「H」),往往在随后的迭代中被不准确地替换。
另一方面,CLLMs表现出了预测正确token的能力,即使在先前有错误token的情况下,也确保token保持不变。
作者将这样的token称为「固定token」。这两种现象共同促成了CLLMs在Jacobi解码中的快速收敛,从而实现了相当大的生成速度提升。
研究团队还观察到,通过训练,CLLMs获得了一个关键的语言概念——搭配:「一系列词或术语,它们的共同出现频率高于随机机会所预期的。」
语言不仅由孤立的单词组成,而且还严重依赖于特定的词对。搭配的示例在自然语言和编程语言中都很丰富。
它们包括:
动词+介词组合(例如「talk to」,「remind ... of ...」)
动词+名词结构(例如「make a decision」,「catch a cold」)
许多领域特定的句法结构(例如「SELECT ... FROM ...」,「if ... else」用于编程)。
一致性生成目标使CLLMs能够从Jacobi轨迹的任何点推断出这样的结构,促进CLLMs掌握大量的搭配,并因此同时预测多个词以最小化迭代步骤。
参考链接:
https://hao-ai-lab.github.io/blogs/cllm/




























